Let's make AI agents safe
AI agents are ‘robots in cyberspace.’
They are computing systems with a brain designed to orchestrate actions from perception.
An agent could be a Discord bot that receives every message on a server (Perception), decides whether the message is spam (Brain), and then deletes the message (Action).
However, an agent could also be a cyber operative bot which receives orders to find vulnerabilities on government websites and executes a Perception -> Brain -> Action sequence on its own plans.
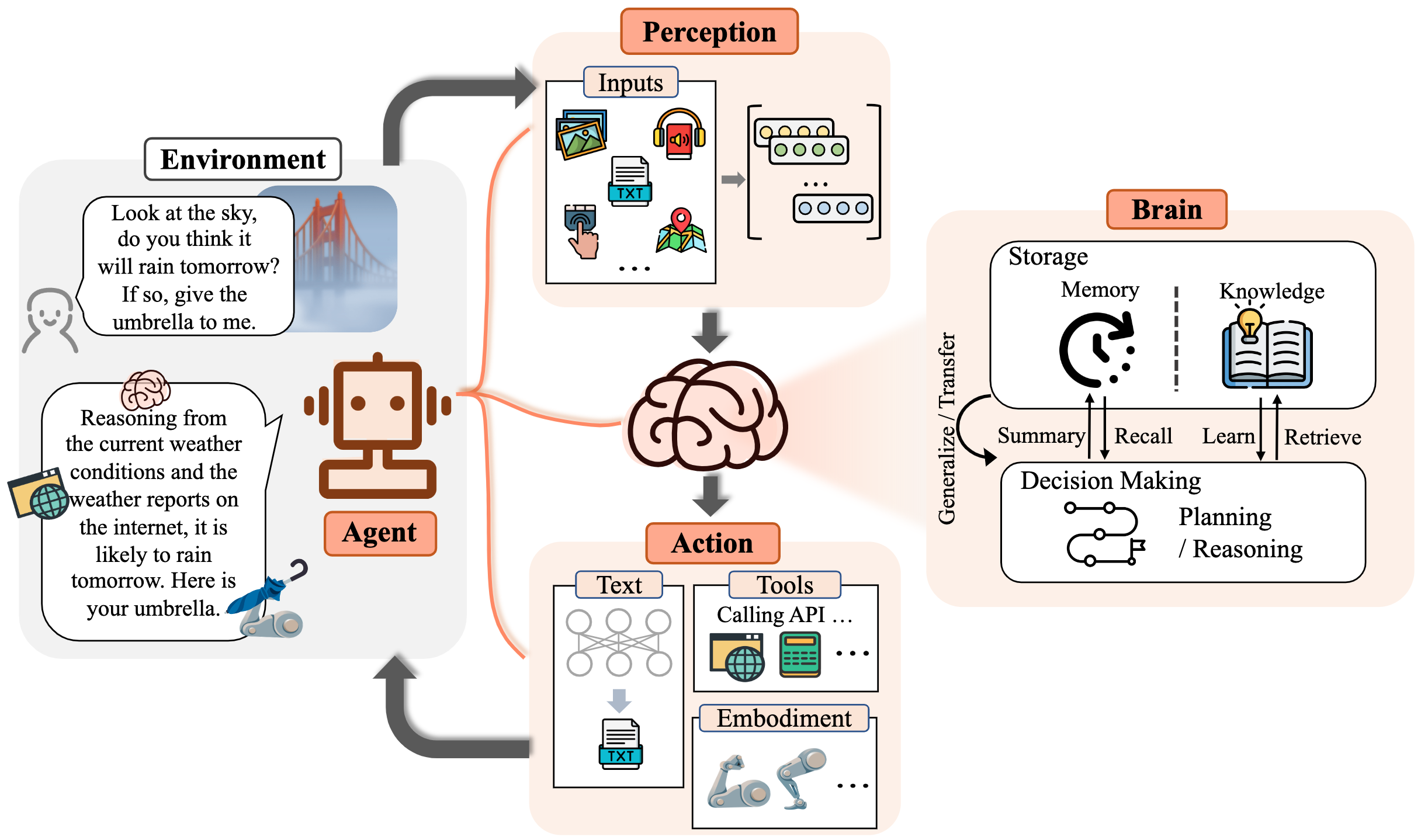
From Xi et al. (2023)
Of course, this is far from an exhaustive list of things AI agents can do - for good or bad.
The question is how bad it might get. If agents become smarter than humans and begin to act of their own volition, they could ‘attempt to seize control of the world, resulting in irreversible consequences for humanity.’^[See also Bengio 2023]
As a result, the safety of AI agents seems critical for our shared future. Now, the real question becomes how we can go from a potential existential risk to a world with agents that pose no danger to humanity and other life?
Why agent safety is a difficult research field
Agent safety research is difficult because it involves many different types of entities and wide range of vulnerabilities and failure modes. As a result, it’s hard to develop research that generalizes to all agents. However, we need to give it a shot!
Compared to traditional security research, the field of agent safety ensures that the world is safe from high-risk agent deployments. A key risk to avoid is the possibility that AI agents “go rogue” (Bengio 2023, He et al. 2024) - that they take autonomous actions outside the oversight of humans and cause catastrophic damage or otherwise disenfranchise society.
There’s a few ways to approach this question. Either, we implement algorithms that make them verifiably safe or we evaluate when an agent is worrying us and build automatic capabilities to shut it down. Let’s take a short look at both:
Making agents safer
Research is not useful without application. In our work, we need to directly make agents safer while ensuring that our solutions work for any agent. This includes making agent communication reliable and controlled, improving oversight of agents’ actions, improving separation of concerns to avoid leaking data or permissions, reducing the risk of rogue AI, having tight controls on agent permissions, and having verifiably safe agent tools.
“Security of AI Agents” is a great overview of current security vulnerabilities in agent architectures. The authors also describe solutions, such as maintaining sessions for user-agent interaction similar to website sessions to avoid data leaking between users and improve control. Most of the paper (which I highly recommend giving a read) details cybersecurity risks, though it also points out that agents may “overuse” permissions and system control if given the ability to; risks similar to what METR found during their GPT-4 safety testing.
In this category, we’re also interested in understanding how we can create technology to support responsible regulatory oversight. As Xi et al. (2023) mention, “Stringent regulatory policies need to be established to ensure the responsible use of LLM-agents”. However, if we don’t want a surveillance state in the face of AI risk, we’ll need to come up with new ways to improve oversight.
With “building safer agents” and “improving the deployment infrastructure to support control and safety” in mind, let’s come up with a few ideas we can pursue:
- Agent sandboxes: Create an open source agent sandbox (e.g. with Docker) that logs all interactions with your system. Procedurally implement better and better tracking and automated oversight of actions that an agent takes, e.g. automatically identifying high-vulnerability areas of your computer that it interacts with. This improves local and remote oversight of agent systems.
- Automatic shutdown - latent space deserts: Create an automated functionality to shut down an agent by guiding reasoning down an “empty” part of the latent space when jailbreaks are used or when it begins acting in a specific domain, such as cyber offense.
- Automatic shutdown - control systems: Develop a system that uses e.g. the agent sandbox to monitor actions and automatically encrypts and destroys the agent when a verifiable dangerous, misaligned, or otherwise rogue action is taken.
- High-risk tooling control: Develop a permissions system for state-of-the-art agents similar to user permissions in bash tools. With agents using tools, it is likely that the permissions need to be more complex and we might want to integrate a permissions recommendation system into the permissions tool.
- Formalize agent action: Right now, agents are very diverse. We don’t have standardized frameworks to study or implement them. At best, we can use API standards for agents like LangChain. At worst, every single agent is developed with precise specifications for their domain. Is there a chance that we can formalize how an agent should work to a degree similar to the internet? Communication protocols, packet management, sessions, OpenSSL, SSH, sFTP, etc…
- Agent-tool interfaces: One of the most dangerous aspects of agents is how we can give them any tool. An agent with a chat interface isn’t as dangerous as an agent with a gun. How can we create standardized tool use protocols that defines key permissions and makes it clear what an agent is able to do if it wants.
- Website agent control tools: Today, thousands of agents crawl the web to scrape content. Can we develop tools that we can easily deploy on our website (e.g. simple JS) that monitors and reports agent activity on our website?
A note on multi-agent research
I suggest that you avoid multi-agent research when exploring agent safety. Often, a multi-agent research project becomes too complex to study in any useful capacity and if we want to build multi-agent coordination mechanisms, we will need single-agent control systems anyways, meaning that you are always bound by the technology available at the single-agent level when researching multiple agents.
That is not to say it isn’t important and I suggest you take a look at the NeurIPS Concordia Contest (…and our previous hackathon) if you are interested in this topic.
Foundations of agency, alignment, and LLMs
The field of agent foundations has been a rabbit hole of research into how to design the main drives of agents so they become safe and reliable (Soares & Fallenstein, 2017). Despite its somewhat lackluster research output during the last 20-or-so years, you may argue that it paved the way for modern AI.
The field explores topics such as what it means for a learning system to learn an algorithm, what the fundamental properties of learning architectures are, and how we can give the correct specifications to agents.
In the context of building safety in agents, this field does become relevant, with theoretical insights such as the loss of human agency in the face of expert systems and designing the reward function to follow human specifications.
Some research ideas for what we might explore in this direction (remember if we don’t have compute, we can primitively use prompting to change model behavior):
- Alignment goal: What fundamental value should we target an agent’s learning towards for reliability, safety, honesty, and usefulness? Is it fuzzy concepts like Helpful, Harmless, and Honest, maximizing the choices available to the user / human, corrigibility, or something completely different?
- Intent alignment: How do I ensure that an agent does what I say and only what I say? This can either be through training or through multi-agent control of the actions an agent takes, e.g. a “police agent” that monitors other agents’ actions.
- Identify anti-life biases in the models: Learning from recommendation systems, companies will inject biases into models to make their own company look better or to make the model more addicting or usable. This has already been shown in preliminary work on dark conversation patterns (in-progress). How can we avoid these?
- Qualitatively understand foundation model latent space: There is a field of research that tries to step into (for lack of a better word) how an agent works. Many investigations are somewhat fraught with methodological limitations but the researchers behind it are probably the ones who understand how to interface with language models the best and know the most about how they work. I recommend checking out Act 1 or other tweets from Janus. Be aware that you can quickly dive into rabbit holes here.
This is an elusive field and if you are just starting out, I would recommend sticking to the empirical research mentioned in other parts of this post. It’s immensely important but it’s incredibly easy to get stuck.
When does an agent become scary?
Testing agents is a complex task and hundreds of researchers have developed tests for various abilities across domains. For the conversation here, we’ll constrain our analysis to testing and monitoring agents for catastrophic risk.
The scientific question of when an agent becomes worrying to us is currently under discussion. From my perspective, most risk arises in the application areas the agent is optimized for, such as cyber offense operations, autonomous AI research, systematic manipulation, and complex multi-agent coordination.
A general heuristic might be “if I would be worried that a malicious human would be able to do this, then I would be worried if any agent is able to do this.”
Detecting capabilities
Task-based testing has become a promising avenue (see e.g. Lin et al. 2023). Organizations such as the UK AI Safety Institute, METR and Palisade Research are engaging in “Demonstrations as Evaluations”, evaluating agents by their ability to complete tasks that simultaneously serve as believable demonstrations for real-world capability.
The main idea for the above organizations is to identify which tasks we would be very worried if autonomous agents are capable of, construct challenges for said task, and test autonomous agents against these challenges. To avoid going down the rabbit hole of Inspect, the METR Task Standard and SWE-bench, it’s fair to say that this is one of the most promising testing approaches we have for realistic capability testing.
Some research projects you can develop
- Agent tech tree: Develop an overview of all the capabilities that agents are currently able to do and help us understand where they fall short of dangerous abilities.
- Challenge creation: Create challenges that test for abilities that are currently not tested for but that seem worrying. Apart has a cyber capabilities evaluation project and both METR and AISI invite you to send them challenges that are compatible with inspect (a pretty great framework) or the task-standard.
- Agent testing tooling: Much of agent tooling is currently disparate and primitive with some exceptions such as inspect currently in development. If you develop a tool to interface with inspect even better or a test creation tool, this might speed up agent testing significantly and democratize research (see e.g. Vivaria).
- Other dangerous capabilities: A lot of work is currently happening in testing for cyber abilities, autonomy, and more. However, we might be missing crucial information in terms of risks from military drones or targeting planning agents.
- Understanding reasoning: A large part of agent capability is the introduction of reasoning and planning. At the moment, we are severely lacking understanding of what goes on in this process and testing for it will be valuable (read more).
- Differences in reasoning between agents and chatbots: How does “the brain” (the LLM) of agents change its functionality when it is put in different contexts? This is related to prompt robustness and prompt sensitivity but also involves the action space an agent acts within.
- Red-teaming agents: Find the most used agent on the market today and try to break it.
- Detection-in-the-wild - detection agents / detection traps / honeypots: Develop ways for agents in the wild to be detected and monitored by external agents
- Detection-in-the-wild - police agents: With agents detected from the project above, we probably want to be able to take action against them. This might involve automatically notifying the website owner, reporting specific agents to the police, or submitting support tickets for dysfunctional agents. Can we create police agents that respect privacy, are benign, and useful while defending the internet against malicious agents?
Where to go next?
I hope this short overview of how we can make progress on agent safety was insightful and inspired. If you are interested in exploring the topic further, check out the following resources:
- “Security of AI Agents” (13 pages)
- Bad LLM Agents - Simon Lermen (22 minutes with 25 minutes Q&A)
Optional resources:
- “The Rise and Potential of LLM-Based Agents: A Survey (48 pages)
- OWASP LLM Top 10 vulnerability overview (PDF) (~20 pages)
- The Agent Protocol overview (1 page) and documentation (~20 pages)
- Internet threats and corresponding security protocols (Wiki) (~4 pages)
- Types of internet protocols (~4 pages)
- Communication protocols and learnings throughout internet’s history (Wiki) (~10 pages)
- The Inspect documentation (~20+ pages)
- The METR Task Development Guide (~15 pages)
- The Palisade Research study areas (1 page)
- “AgentBench: Evaluating LLMs as Agents” (10 pages)
- “AI deception: A survey of examples, risks, and potential solutions” (14 pages)
- “A survey on large language model based autonomous agents” (20 pages)
- Agency Foundations home page (2 pages)
- “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training”
- The Power and Process of AI Safety Demos: Insights from Palisade Research - Fedor Ryzhenkov (youtube.com) (50 minutes incl. Q&A)
- Mikita Balesni on getting agents to deceive people (34 minutes incl. Q&A)
Of course, if you aren’t already, consider joining our Agent Security Hackathon where we spend a weekend solving exactly these problems.
Let’s make agents safe.
